
この記事ではAWSのサービスの1つである、AWS Lambdaに関してまとめていきます。
以前僕もそうだったように、Lambdaを使ってみたいけどいまいち使い方がよくわからなくて結局後回し、という人も多いのではないかなと思います。
今回は、そのような人でも理解していただけるように、
Lambdaの概要- 画面の使い方
- 1つ1つ手順を整理しながらサンプル機能を実装
という内容でやっていきます。
今回サンプルとして実装してみる例は、
「S3に画像ファイルをアップロードした際に起動して、その画像ファイルをダウンロードして、別のフォルダにアップロードする」
というのを実装していきます。
理解するには実際に手を動かしながら実装していくのが一番早いと僕は考えているので、そうしやすいように、1つ1つの手順をスクショを使ったりして説明していきます。
AWS Lambdaとは
まず読み方ですが、Lambdaは「ラムダ」と読みます。
Lambdaは、あるイベントが発生したときに実行する処理の関数だけを実装すれば、あとはサーバの設定や管理などは全てLambdaが行ってくれるというサービスです。
一般的なサーバを使用する場合
・立ててから環境構築していかないといけない
・高負荷にも耐えられるような日々の運用管理
・セキュリティ対策
・障害が発生したときの対応
などやることはいっぱいあるかと思います。
ですがLambdaを使用する場合、そういったことは全てLambdaにおまかせして、単純に関数の実装だけに専念することが出来ます。
サーバーレスアーキテクチャ
最近「サーバーレスアーキテクチャ」が注目度が上がっていますが、その代表的なサービスの1つがLambdaです。
「サーバーレス」というのは、プログラマがサーバーの設計や運用を気にしなくて良いというような意味合いです。
「サーバーレス」という単語の意味だけ考えると、サーバーを使わないという様なイメージになりやすいですがそういうわけではなくて、Lambdaに関しても、サーバーの設定をしなくても大丈夫なだけで、内部的にはサーバーが起動しています。
Lambdaの料金
Lambdaの料金に関しては、
Lambda関数のリクエスト数Lambda関数のメモリに応じた実行時間
に応じて決まります。
リクエスト数に関しては、100万件あたり0.20USDとなっています。
メモリに応じた実行時間に関しては、
料金 = メモリ(GB) × 実行時間(秒) × $0.00001667
というかんじになっています。
例えば、1GBのメモリで1秒実行したら0.00001667ドル料金が発生する、というような具合です。
Lambdaの料金に関して、詳しく知りたい方はこちらの記事で詳しく説明されています。
https://qiita.com/Keisuke69/items/e3f79b50b6039175401b
無料枠に関して
実際に動かしてみて学びたいという方は、こちらが気になるかと思います。
Lambdaには無料枠が用意されていて、内容は以下になります。
- 月間100万リクエストまで無料
- 1GBの関数を月間40万秒まで無料で実行できる
これらはアカウント作成から1年間ではなく、無期限で適用されます。
試しに使って見る程度であれば、無料枠内で十分に使えるかと思います。
Lambdaで使える言語
・Python 2.7, 3.6, 3.7
・Node.js 6.10, 8.10, 10.x
・Java 8
・Ruby 2.5
・Go 1.x
・.NET Core 1.0(C#), 2.1(C#/PowerShell)
この記事では詳しく触れませんが、カスタムランタイムを使用すればそれ以外の言語も使用できるみたいです。
今回作っていくサンプル
今回は、S3に画像ファイルがアップロードされたときに、その画像ファイルをダウンロードして別のフォルダに再アップロードする。
という処理をLambdaを使って実装していきたいと思います。
使用する言語は、Node.js 10.xを使っていきたいと思います。
(バージョン10は最近使えるようになったばっかりです。)
関数の作成
まずはAWSのコンソールでLambdaの画面を開きましょう。
リージョンは東京リージョンです。
↓Lambdaのトップページで「関数の作成」を選択しましょう。
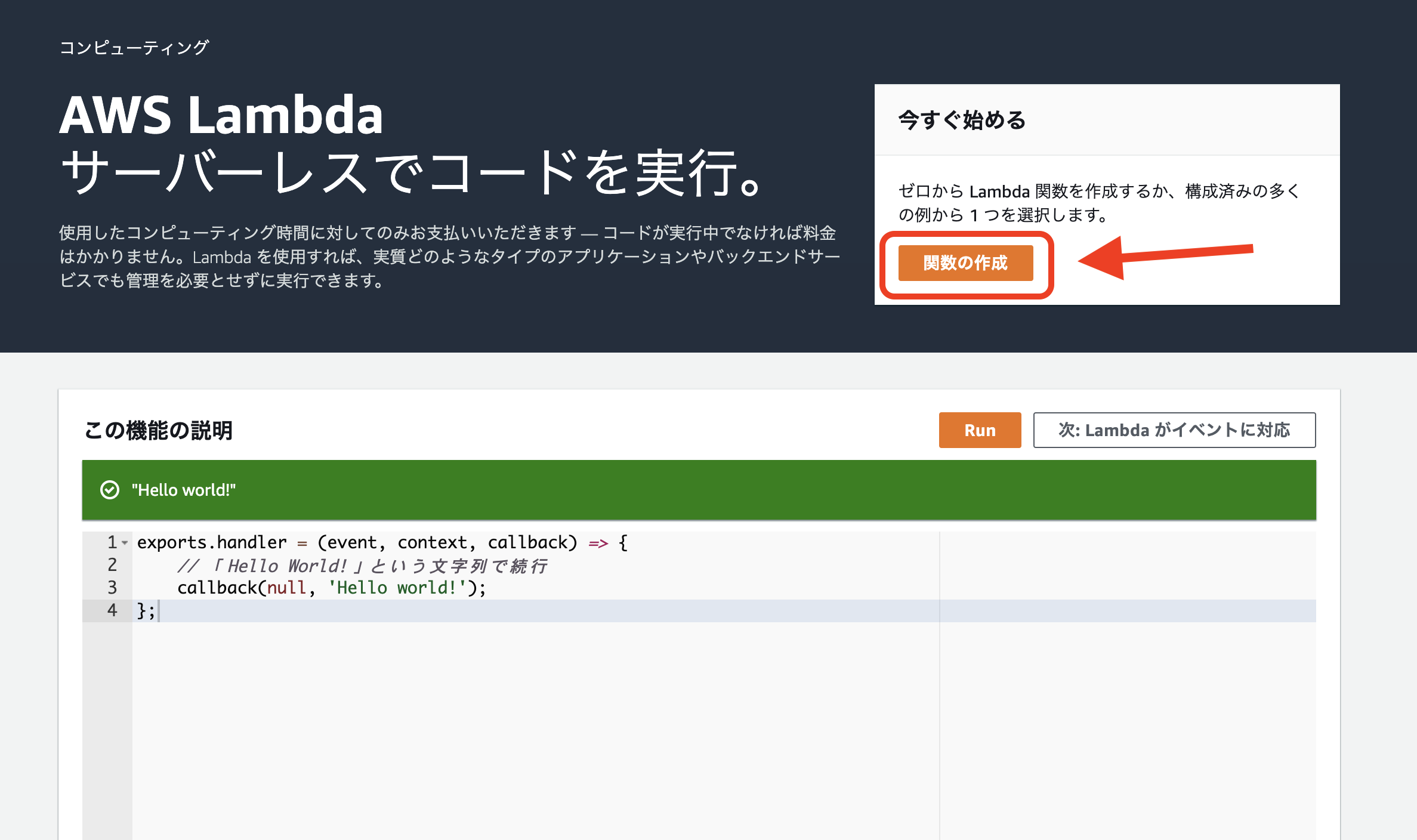
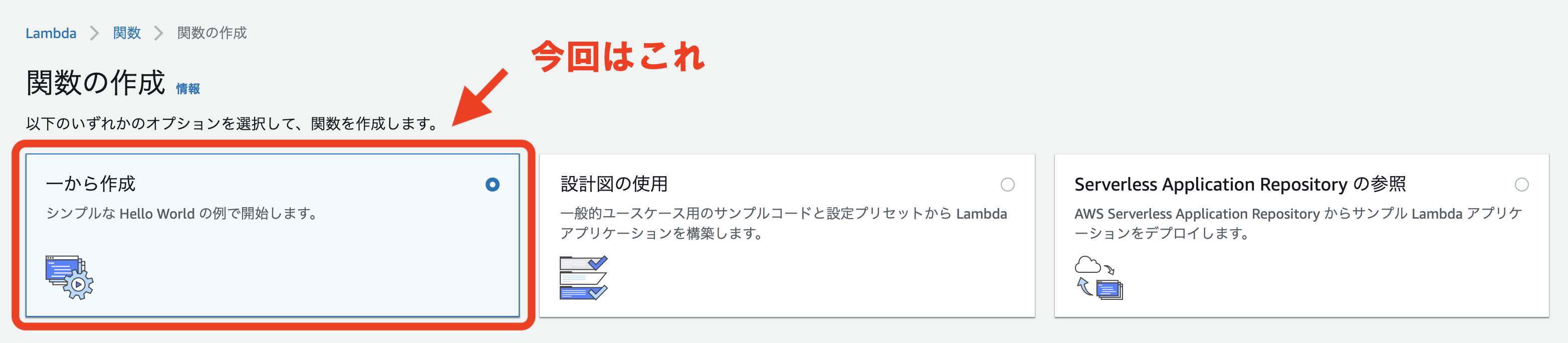
↓「関数の作成」の画面になります。
一から作成するのか、用意されているサンプルを使用するのかを選択できます。
今回は「一から作成」を選択します。
↓次に関数の基本的な情報を入力していきます。
関数名や使用言語の選択、ロールを設定します。
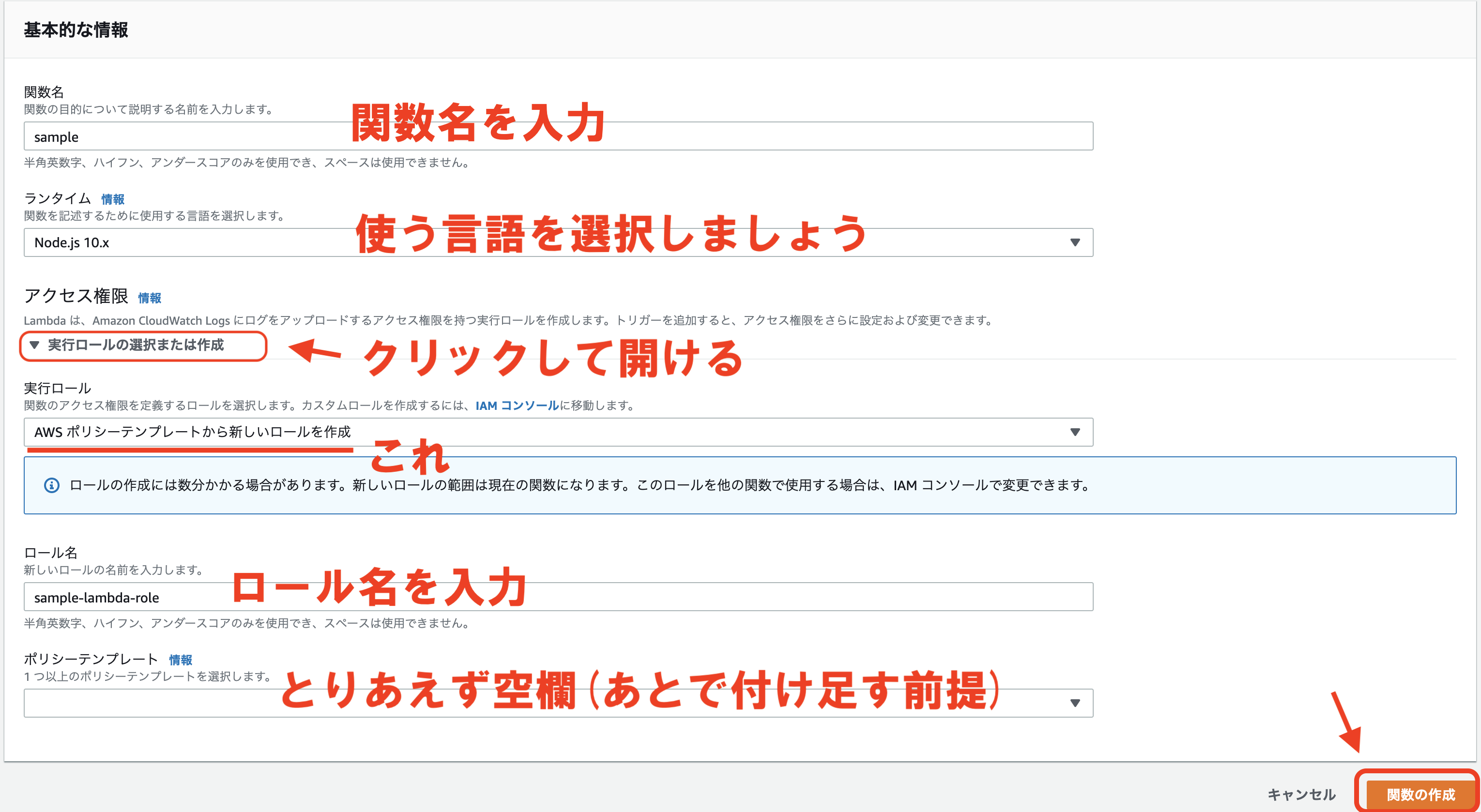
今回はsampleという関数名で、言語はNode.js 10.xを選択しました。
ロールというのはIAMロールのことで、作成する関数のアクセス権限の設定です。
例えば、今回のようにS3のファイルの読み取り書き込みをする場合は、その権限を付与する必要があります。
後から1つずつ付与することもできるので、今回は最低限の設定で必要な段階になったら設定していくことにします。
設定が完了したら、「関数の作成」をクリックします。
そうすると関数の作成が完了して以下の画面になります。
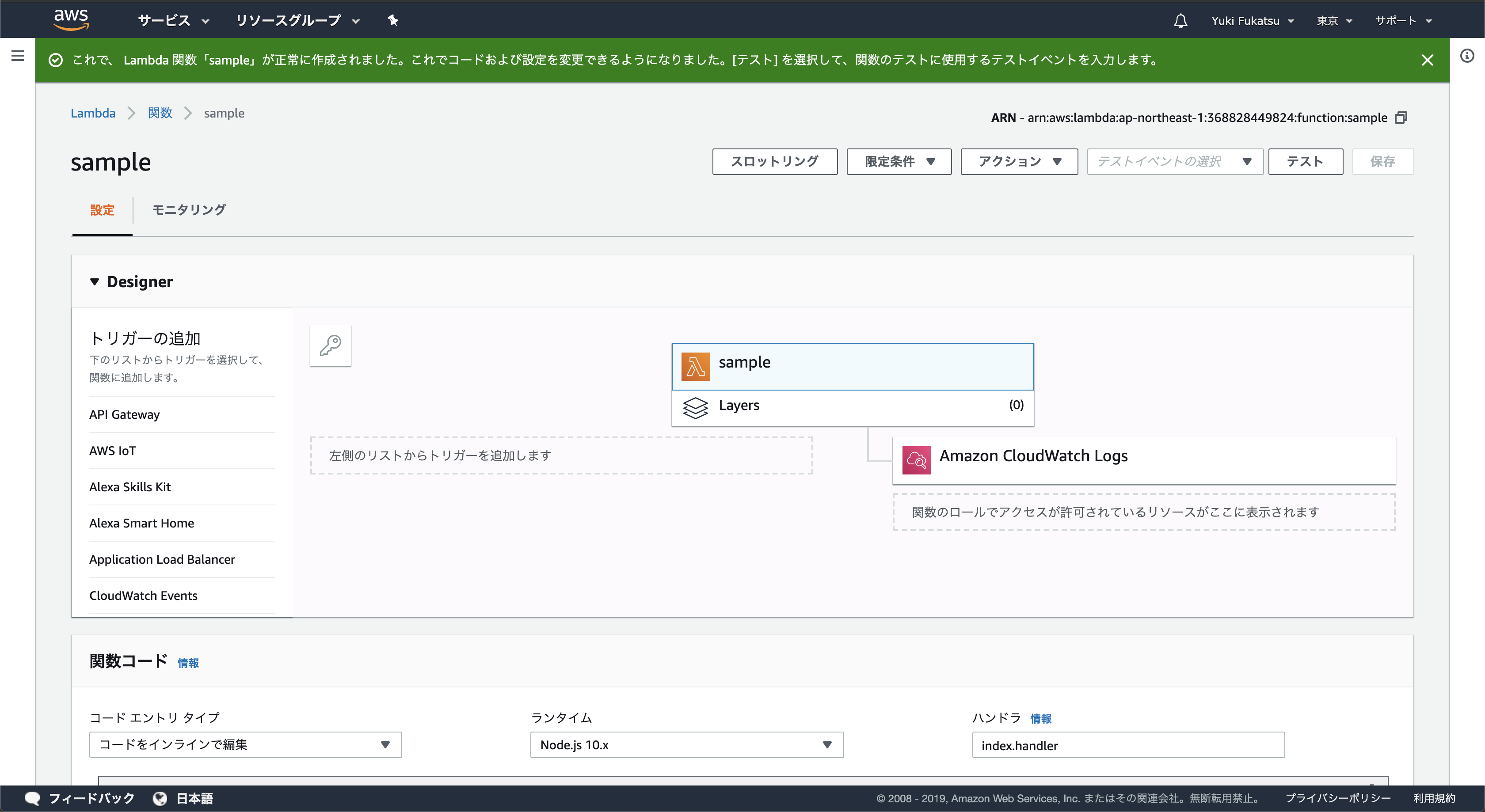
これで関数の作成は完了です。
画面の説明
実装に入る前に、ここで一旦画面の各機能の説明をしていきます。
画面の上から順に設定していきます。
AWSのコンソール画面は頻繁に変更があります。
この記事執筆時(2019年5月18日時点)での画面の説明なので違う部分がある可能性があることをご了承ください。
トリガーとアクセス権
まず画面一番上で、関数のトリガー(この関数の発火装置となるイベント)と関数に付与しているロールが許可しているアクセス権のあるリソースが表示されます。
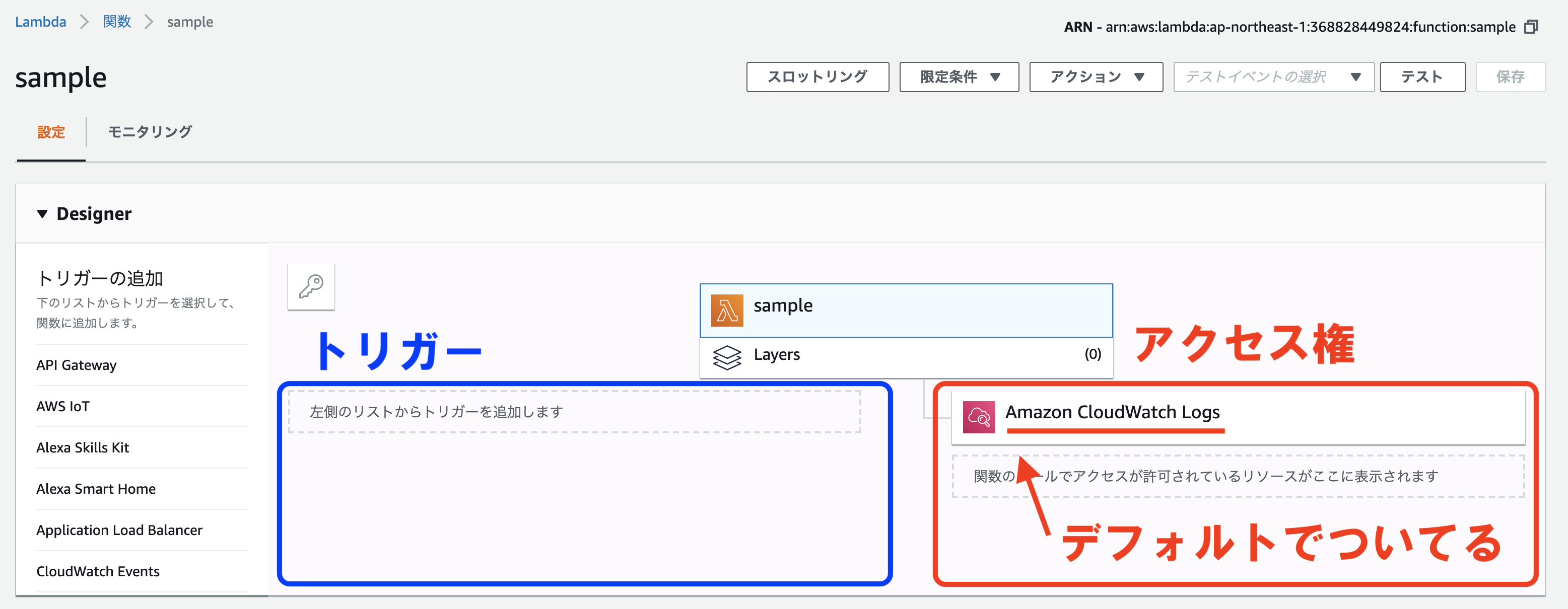
作成時点ではトリガーは設定されていないので空欄です。
左のリストからトリガーを追加することが出来ます。
アクセス権に関しては、関数の作成時にこの関数用のロールを作成しましたが、Lambda用のロールはデフォルトでAmazon CloudWatch Logsのアクセス権が付与されています。
これによって関数のログがCloudWatchで確認することが出来ます。
ログの確認方法に関しては後述します。
コードの編集
次にあるのは「関数コード」という部分で、作成した関数のコードを設定する部分です。
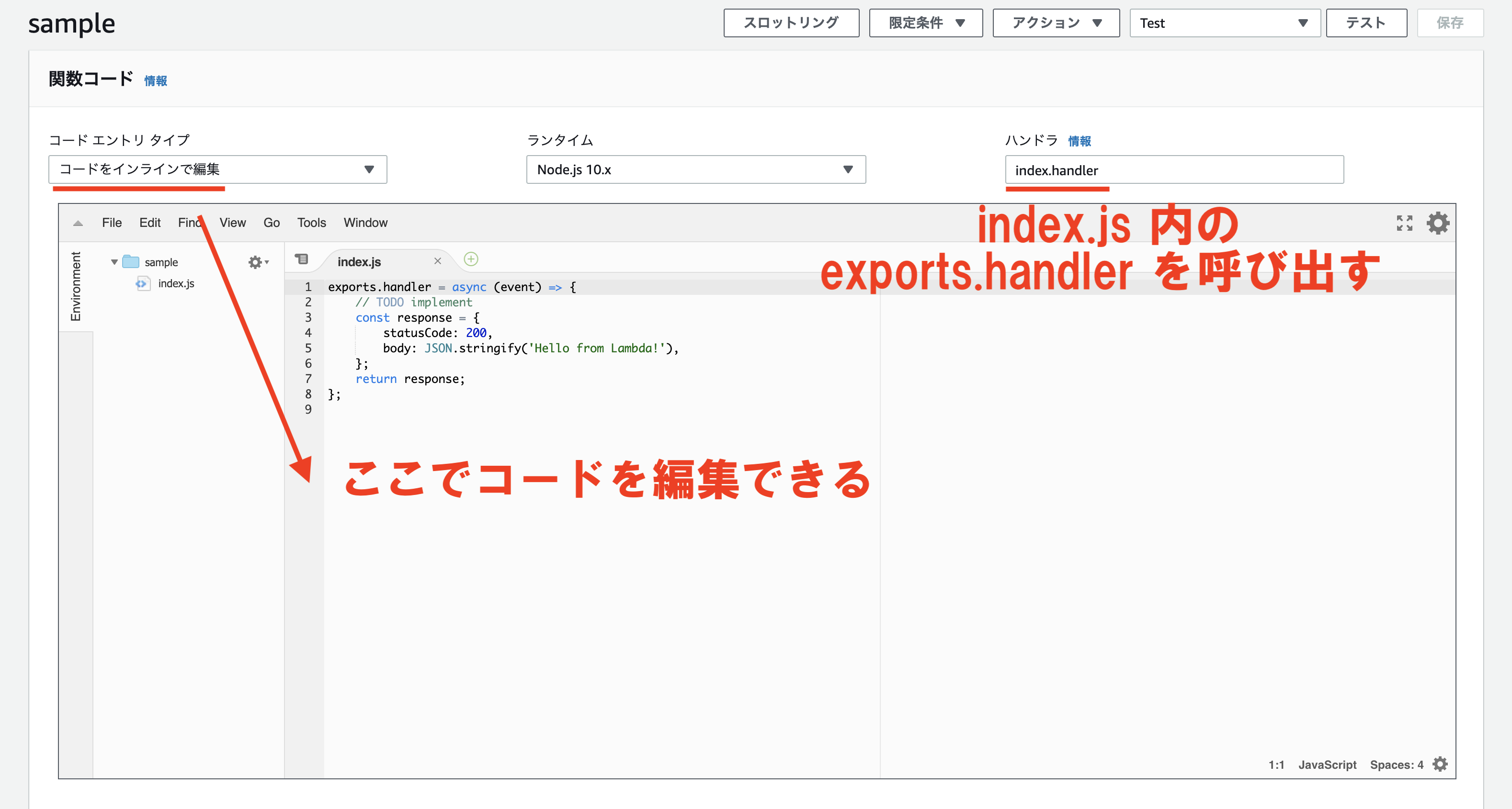
「コード エントリ タイプ」の部分では以下の3種類を選ぶことが出来ます。
| コードをインラインで編集 | 上記のスクショ内のエディタでコードを編集することが出来ます。 基本的にこちらを使うのが便利かと思います。 |
|---|---|
| .zipファイルをアップロード | 別で編集したファイルを.zipファイルにしてアップロードします。データ量が多い場合にはコードをインラインで編集できないのでその場合はこちらを使います。 |
| Amazon S3からのファイルのアップロード | S3からファイルをアップロードすることが出来ます。S3のリンクURLを指定します。 |
今回は「コードをインラインで編集」を選択しました。
「ハンドラ」の部分では、呼び出すコード内の関数を指定します。
Node.jsの場合はデフォルトではindex.handlerとなっていて、これはindex.jsのexports.handlerを呼び出します。
デフォルトで設定されているソースコードを見ていきましょう。
exports.handler = async (event) => {
// TODO implement
const response = {
statusCode: 200,
body: JSON.stringify('Hello from Lambda!'),
};
return response;
};
デフォルトでは、すぐにステータスコード200とHello from Lambdaのメッセージを返すようになっています。
//TODO implementとコメントでなっている部分に、どんどんコードを記述していきましょう。
基本設定とその他の設定
他にも設定があるので、1つずつ見ていきましょう。
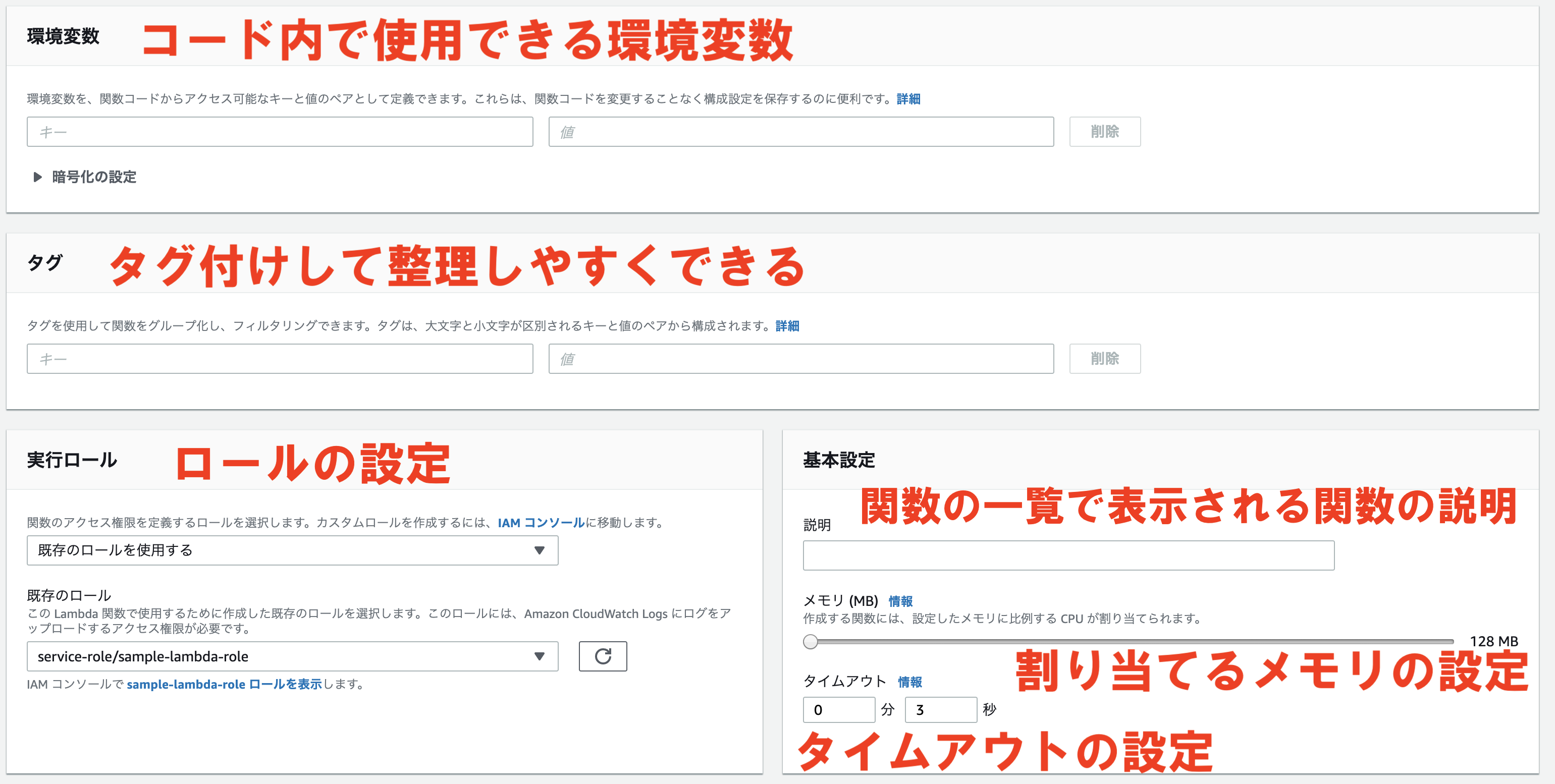
「環境変数」では環境変数を設定することが出来ます。
例えば認証キーのようなソースコードに含めたくないようなものを環境変数で渡すことが出来ます。
node.jsの場合はprocess.env['HOGE']で取得することが出来ます。
「タグ」ではタグ付けを行い、関数一覧画面で整理がしやすくなります。
「実行ロール」ではロールの設定を行います。
作成時にも行いましたが、変更や新規作成を行うことが出来ます。
ロールの内容の変更はIAMのコンソール画面で行います。
「基本設定」ではいくつかの項目があります。
まず「説明」は関数の一覧画面で表示される関数の説明を設定します。
「メモリ」ではメモリの設定をします。
128MB 〜 3008MB(約3GB)の範囲で64MB刻みで設定することが出来ます。
メモリが足りなくなった時点で処理がうまく行かなくなってしまうので、すべてまかなえるような設定をしましょう。
「タイムアウト」では実行可能時間を設定します。
1秒から15分までの範囲で設定することが出来ます。
関数の処理にかかる時間を考慮して設定しましょう。
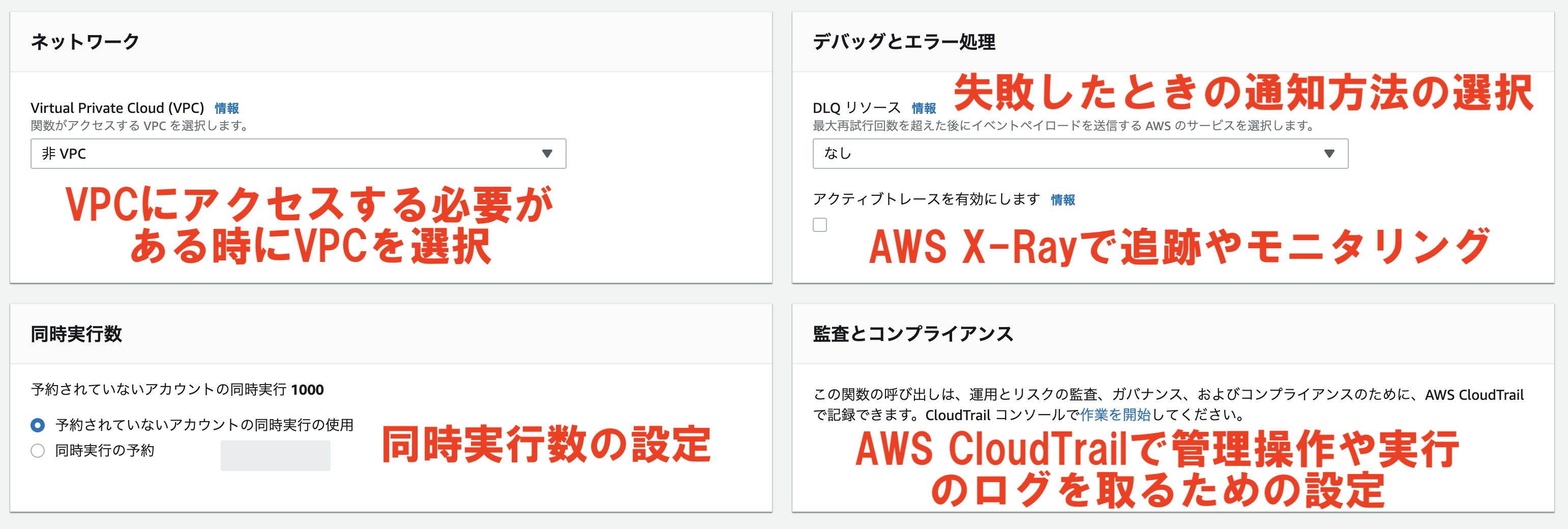
「ネットワーク」の部分では、関数をVPC内に設定するかどうかを設定します。
VPC内に設定する場合はどのVPCにするかも選択します。
VPC内に設置してある他のリソースにアクセスする場合に設定します。
「デバッグとエラー処理」では処理が失敗したときの通知に利用するサービスの設定をします。
「なし」、「Amazon SNS」、「Amazon SQS」のどれかを設定することが出来ます。
具体的な通知の設定方法はこの記事では扱いません。
「同時実行数」の部分では、関数の同時実行数を設定できます。
Lambdaでは、仮に2つのトリガーイベントが発生した場合に、1つずつ実行されるのではなく、同時に2つ並列して実行されます。
その最大同時実行数を設定します。
1つのAWSアカウント内での同時実行数は1000までとなっています。
(利用状況に応じて上限申請も可能)
関数ごとに同時実行数を振り分けることも可能で、その場合にこちらで設定します。
「監査とコンプライアンス」では、AWS CloudTrailを使用して、管理操作や実行のログを取るための設定をすることができます。
具体的な設定方法に関してはこの記事では行いません。
テストを実行
次にテストの実行方法を説明していきます。
こまめにテストを実行し確認をしていくことで開発効率を上げていくことができるので、しっかり使えるようにしていきましょう。
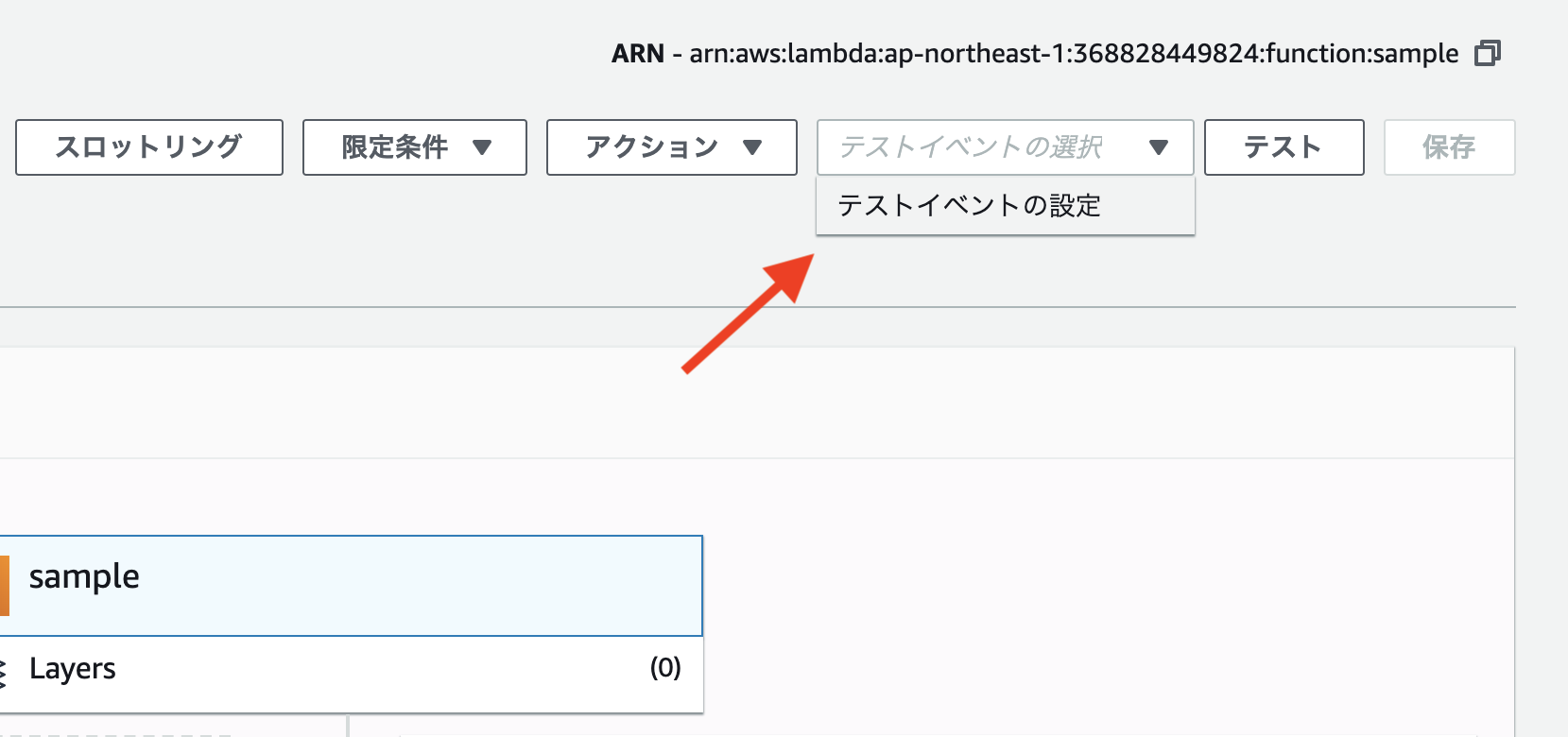
テストイベントの設定
関数の画面の右上の「テストイベントの選択」→「テストイベントの設定」をクリックしましょう。
↓「テストイベントの設定」の画面が出てきます。
自分で1から作るか、イベントテンプレートがある程度用意されていてそれからいじることも出来ます。
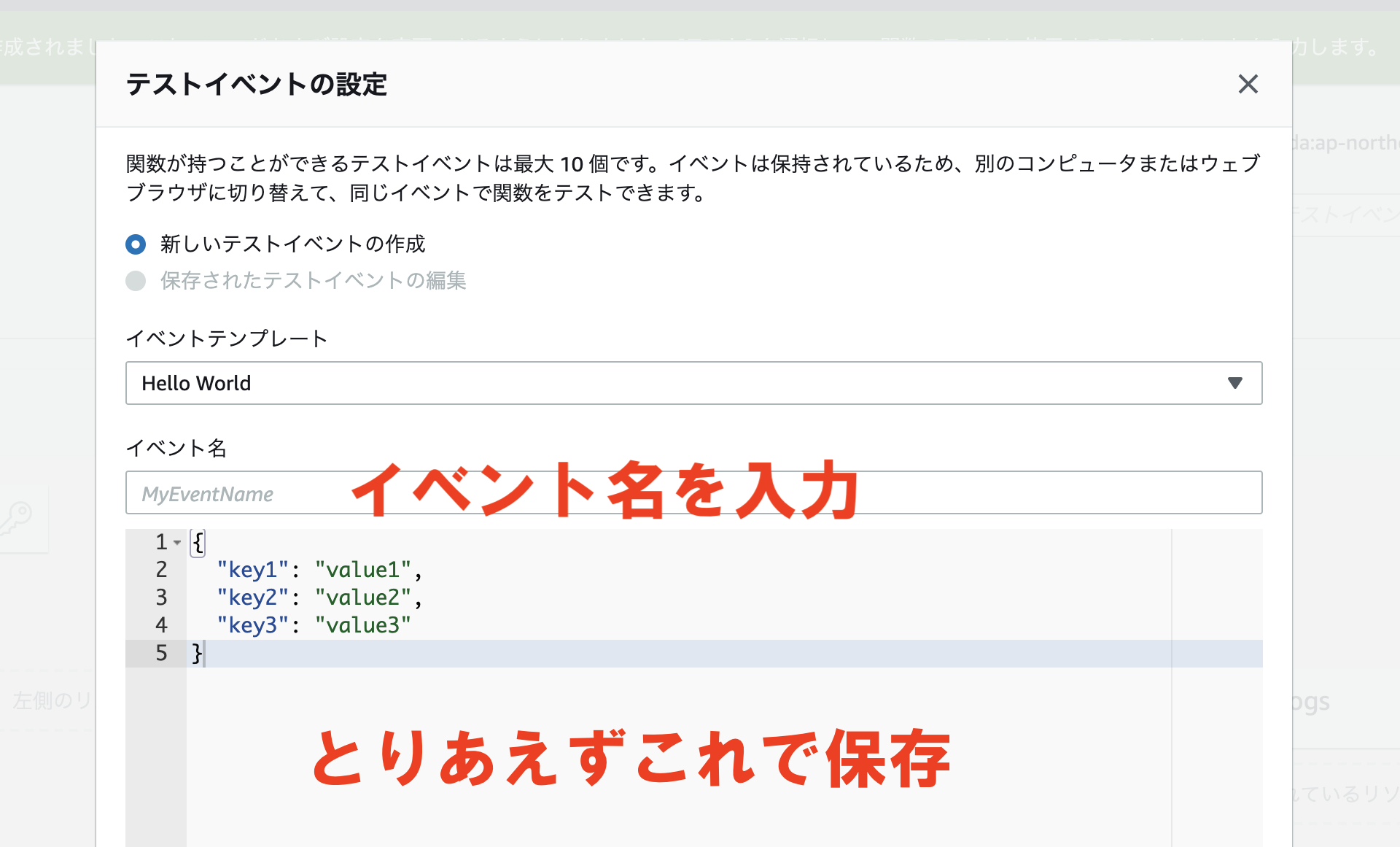
Hello World的なイベントが用意されていて、それを利用して「Test」という名前で簡単なものをとりあえず新しく作ります。
出来たら保存すればテストイベントの作成が完了です。
テストの実行と結果の確認方法
イベントの作成が完了したら右上の「テスト」をクリックして実行します。
デフォルトの設定から何もいじっていないので成功します。
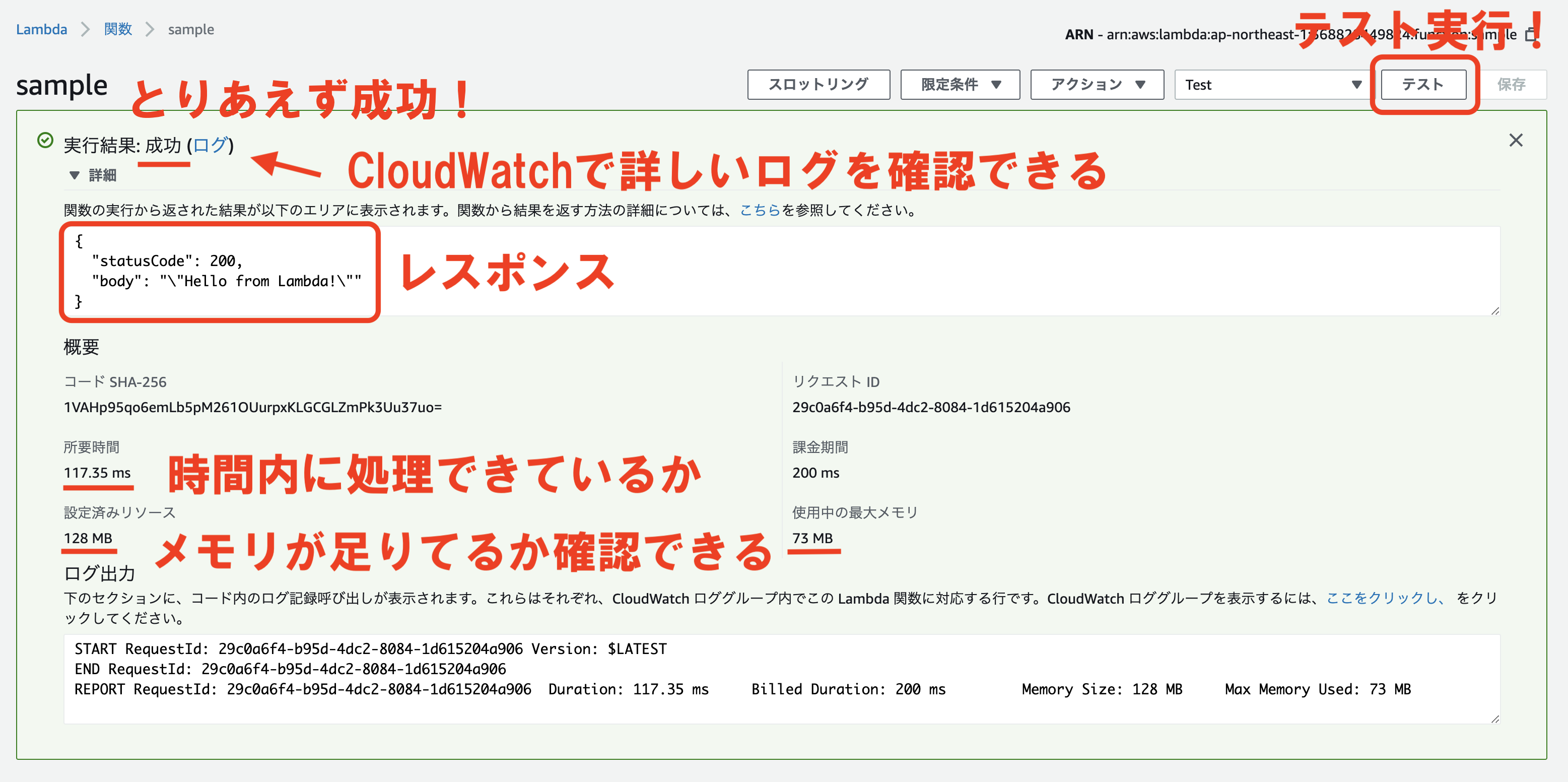
実行結果の画面ではこのあと実装を進めていく上である程度見方を知っておく必要がありますので順番に説明していきます。
まず、「実行結果」の右側に、「成功」か「失敗」かが表示されます。
その隣に「ログ」とありますが、クリックするとCloudWatchの画面に遷移してログを確認することが出来ます。(これに関しては後述)
他には、実行結果のレスポンスを見ることが出来ます。
先程にも説明したときのデフォルトで返しているレスポンスが表示されているかと思います。
「概要」の部分では、いくつか確認すべきことがあります。
確認すべき点は、「所要時間」と「使用中の最大メモリ」です。
先程の設定の「基本設定」のところで、「メモリ」と「タイムアウト」を設定したかと思います。
実行結果の「所要時間」と「使用中の最大メモリ」を見ながら、「基本設定」の「メモリ」と「タイムアウト」が足りなくならないように調整していきましょう。
ログの確認方法
関数にログを仕込むことが出来ます。
ここではログを仕込む方法とログの確認方法を説明していきます。
ログの仕込み方
ログを仕込む方法は、関数のコードに各言語ごとのログのコードを埋め込むだけです。
今回はNode.jsを使用しているのでconsole.log()でログを仕込んでいきます。
Lambdaのコンソール画面上のエディタでコードを以下のように編集しました。
exports.handler = async (event) => {
console.log(event); //追加
const response = {
statusCode: 200,
body: JSON.stringify('Hello from Lambda!'),
};
return response;
};コードを編集したら右上の「保存」ボタンをクリックして変更を保存し、「テスト」ボタンをクリックしてテストを実行します。
↓「実行結果」の「ログ出力」にログが出力されていることが確認できました。

テストイベントとeventの関係
ところでですが、出力した内容はconsole.log(event)としていたので引数で渡ってきたeventを出力しました。
その結果が{ key1: 'value1', key2: 'value2', key3: 'value3' }でした。
これは序盤に設定したテストイベントの内容と同じだということがここでわかるかと思います。
eventには起動元となるイベントの情報が入っています。
トリガーの設定
ここまで、画面の使い方、テストの方法を解説しました。
ここではトリガーの設定をしていきます。
設定方法
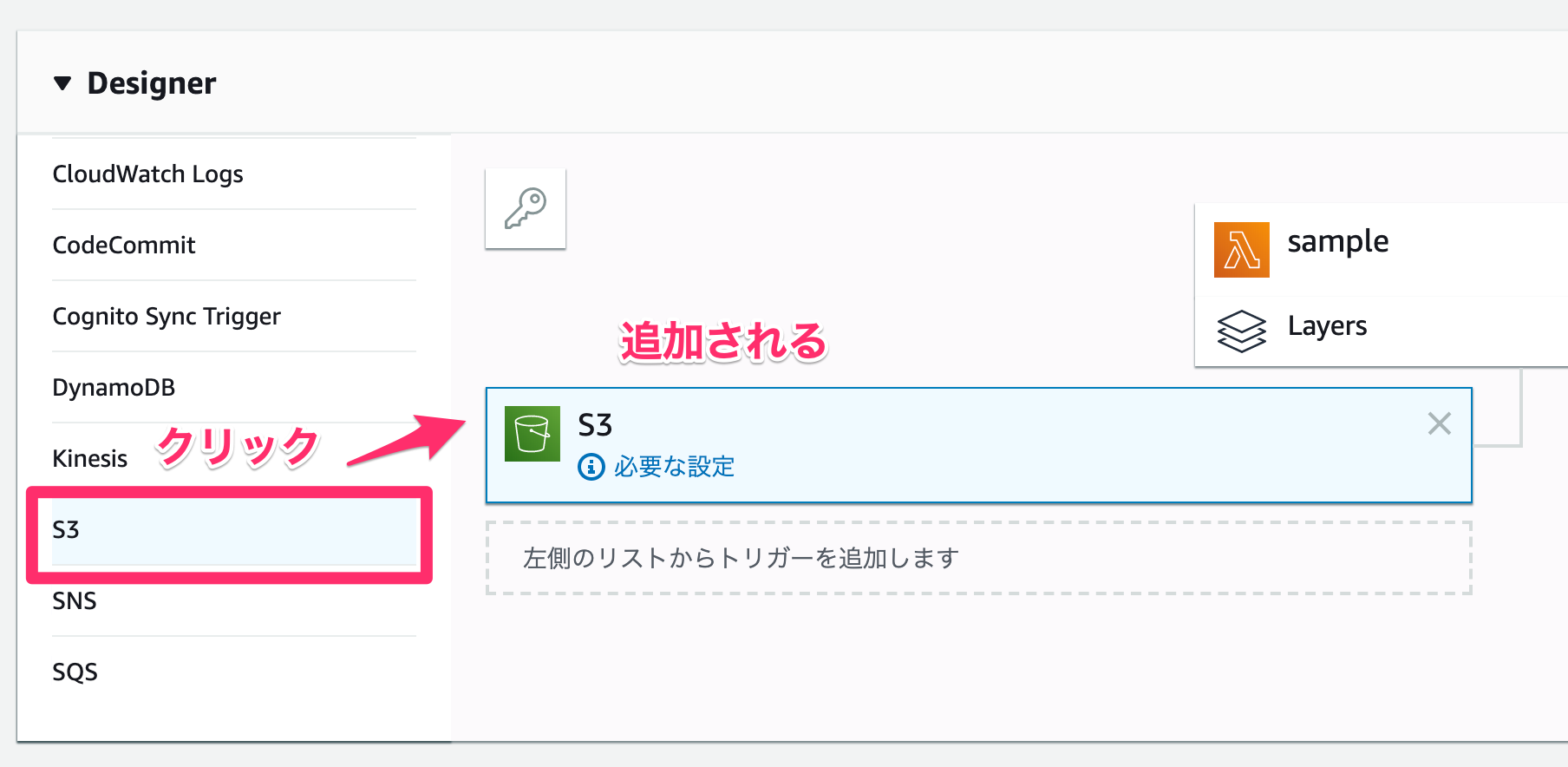
今回はS3へのファイル追加をトリガーとします。
「トリガーの追加」から「S3」をクリックするとトリガーに追加されます。
↓次に下に出現する「トリガーの設定」から設定を行います。
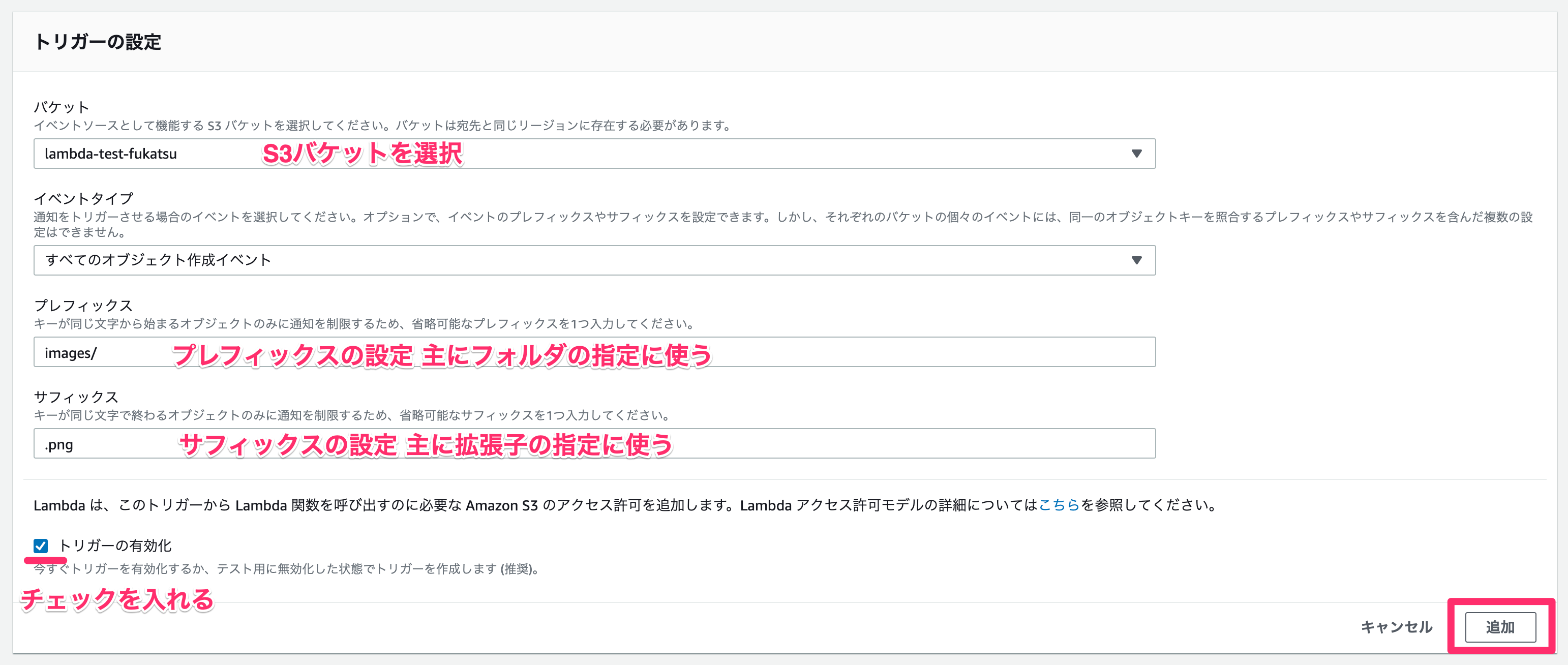
各項目の説明をしていきます。
| バケット | トリガーとするS3のバケットを選択します。 |
|---|---|
| イベントタイプ | S3の場合には、オブジェクト作成の他にオブジェクトの削除など他にもトリガーとなるイベントを設定することが出来ます。 |
| プレフィックス | ファイルの頭文字を指定して、それにあてはまる場合のみ実行されるようになります。S3の場合にはフォルダ名をプレフィックスとすることそのフォルダ以下にファイルが作成された場合にイベントが起動します。 |
| サフィックス | ファイルの末尾の文字を指定することが出来ます。 これによって拡張子で絞ることも出来ます。 |
今回はあらかじめ作成しておいた、lambda-test-fukatsuというバケットのimagesフォルダに拡張子がpngの画像が保存された場合に起動するように設定しました。
設定が完了したら、「追加」をクリックします。
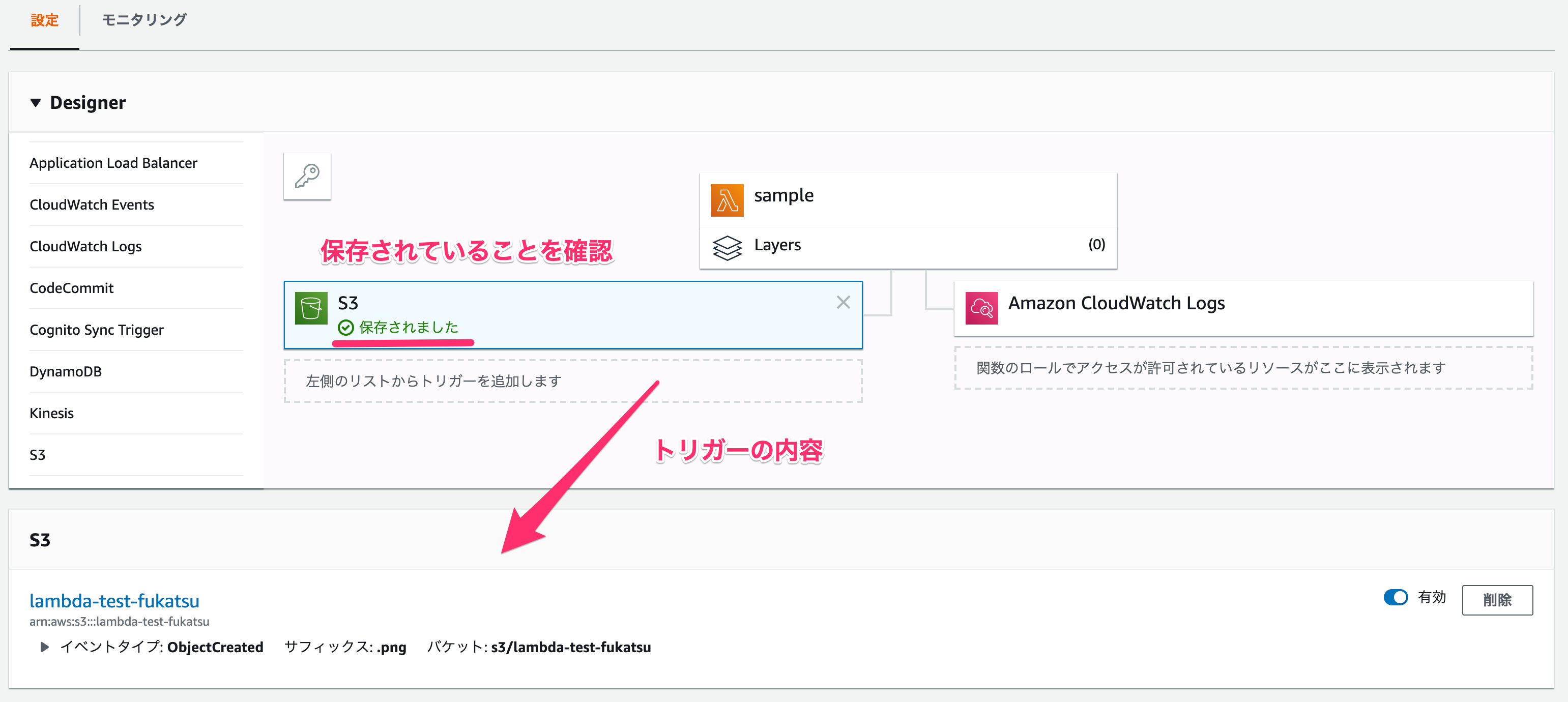
追加ができたら、この時点ではまだ保存されていないので、右上の「保存」をクリックしましょう。
↓保存が完了していると、トリガーの部分で「保存されました」と表示されるはずです。
トリガーから起動できるかを確認
トリガーが設定できたので、実際に起動されるかどうかを確認します。
確認方法としては、今回はS3にファイルがアップロードされたというのをトリガーとしているので、実際にアップロードしてみることで起動させることができます。
その後、Cloud Watchにて起動ログが出力されていれば確認完了です。
↓S3にsample.pngというファイル名で保存しました。
↓Cloud Watchで確認してみると同様の時刻に実行されていることが確認できました。
S3の画面では日本時刻、Cloud Watchの画面では標準時で表示されているので注意です。
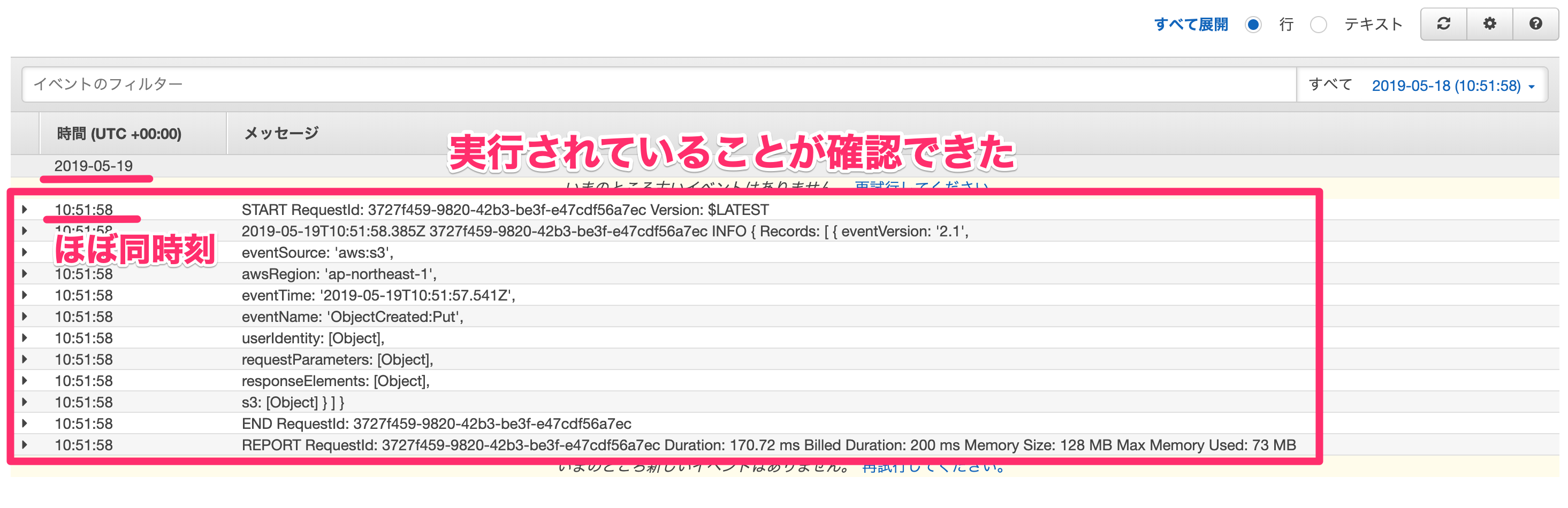
これでトリガーの設定と実行確認が完了です。
ロールに関して
ここで1つ整理しておきたい内容があります。
先程S3のトリガーの設定と実行確認が出来ましたが、ロールは特に変更は行っていません。
現状としてはデフォルトの状態から特にいじっていないので、AWS Cloud Watchのみアクセスを許可している状態です。
これは、トリガーから実行される場合はeventとして、イベントの情報が渡ってくるだけなので、特にアクセスの許可をする必要がないということがわかります。
トリガーと同じ状況をテストする
現状はS3へのアップロードを検知して関数が起動して特に中身の処理は何もしていません。
この後中身の処理を実装していくのですが、その際のテストの方法に関してです。
現状では実際にS3にファイルをアップロードすれば起動されるので一応テストが出来ますが、毎回それをやるのは面倒なのでテストを実行できるようにしていきます。
イベントテンプレートから作成
新しくテストイベントを設定します。
イベントテンプレートにS3用のテンプレートも用意されているので今回はそれを利用していきます。
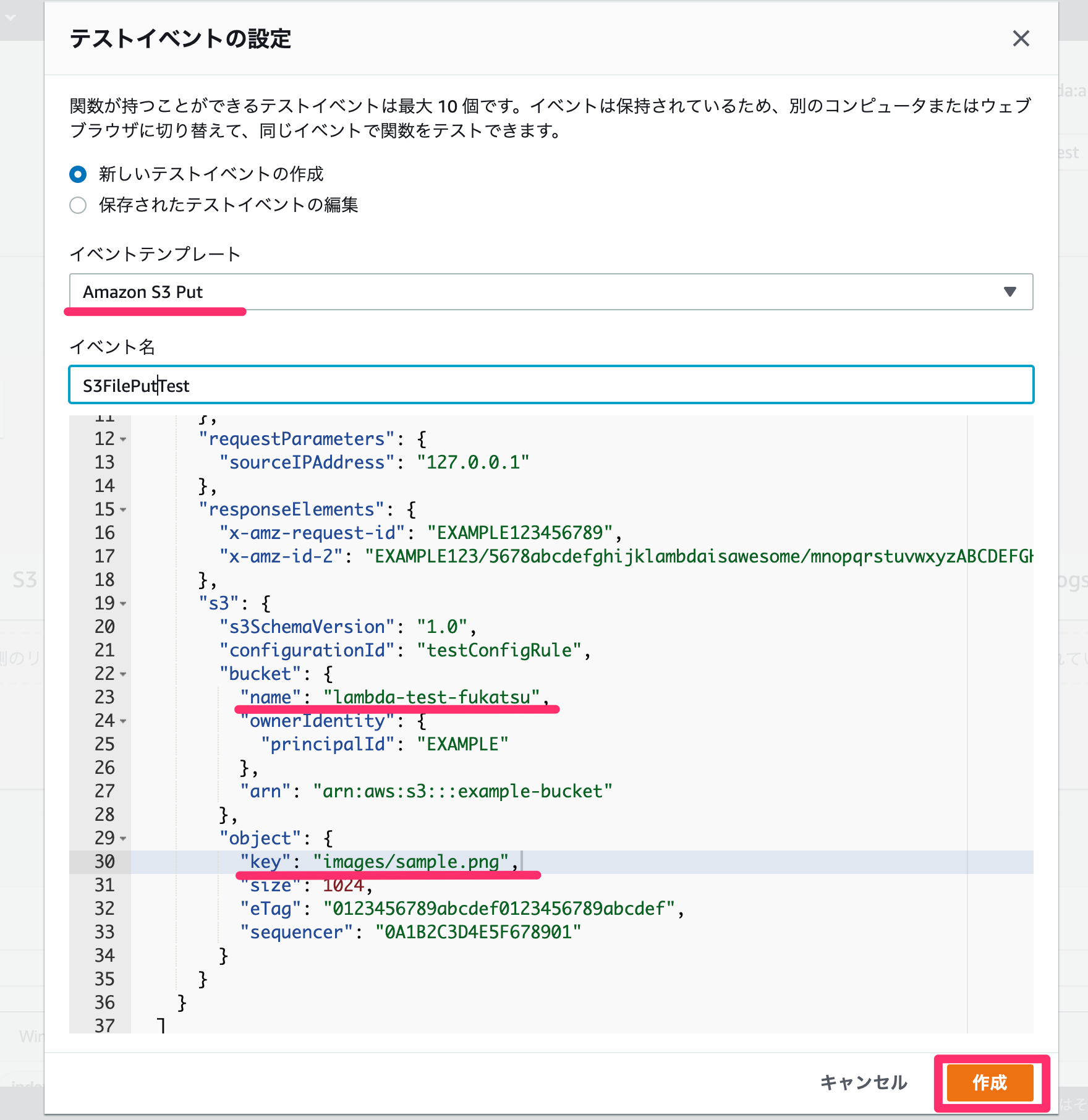
この後の手順として、eventからバケット名とファイル名を取得して関数内でS3からファイルをダウンロードすることを行います。
そのために先程テスト的にアップロードしたイベントを最低限再現するためにnameとkeyの部分だけ変更しました。
設定が出来たら「作成」をクリックします。
これ移行はこの作成したイベントでテストを行っていきます。
実際のeventから作成
先程はイベントテンプレートからテストイベントを作成しましたが、テンプレートにない場合や、より実際のイベントを再現したい場合の手順を説明します。
実際にトリガーから起動した際のeventを使う方法です。
ログの確認方法の説明の部分でeventをログとして出力するようにしていたかと思います。
console.log(event);
こちらはログにしっかり出力されているかと思います。
↓しかし中身が[Object]となってしまう部分があります。
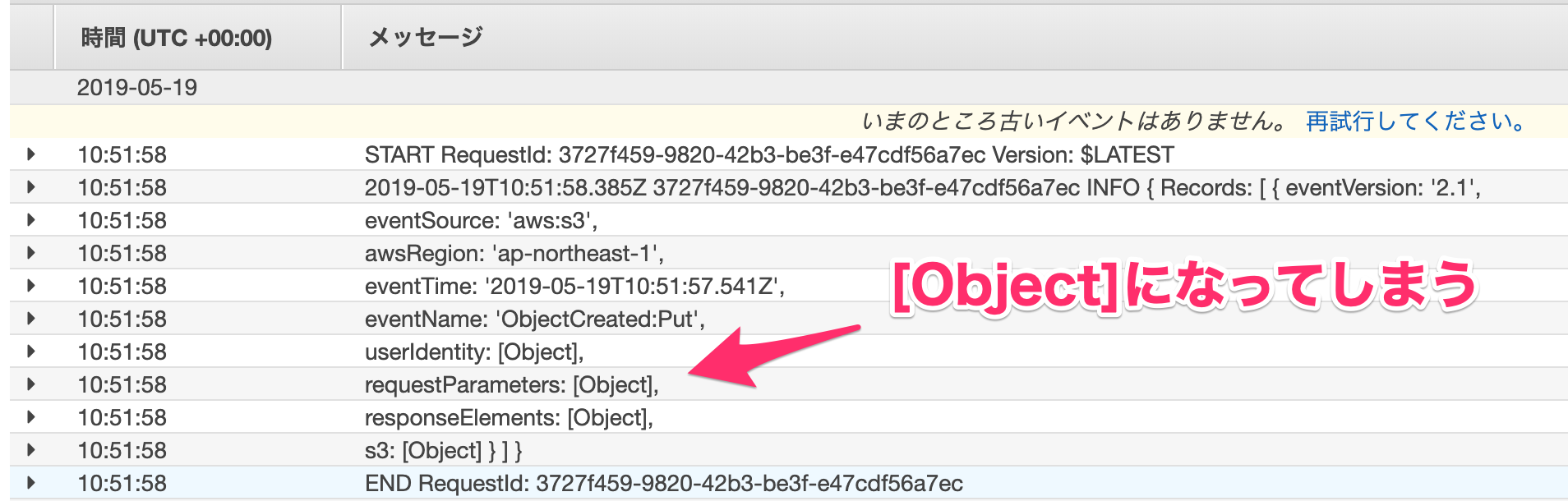
ログの部分のコードを少し変更することで解決できます。
console.log(JSON.stringify(event));
Node.jsの場合は上記のコードになります。
他の言語でもJSON形式に変換することで、詳細も見ることができるようになります。
もう一度S3にファイルをアップロードして関数を起動させましょう。
そうすると以下のようにログを確認することが出来ました。
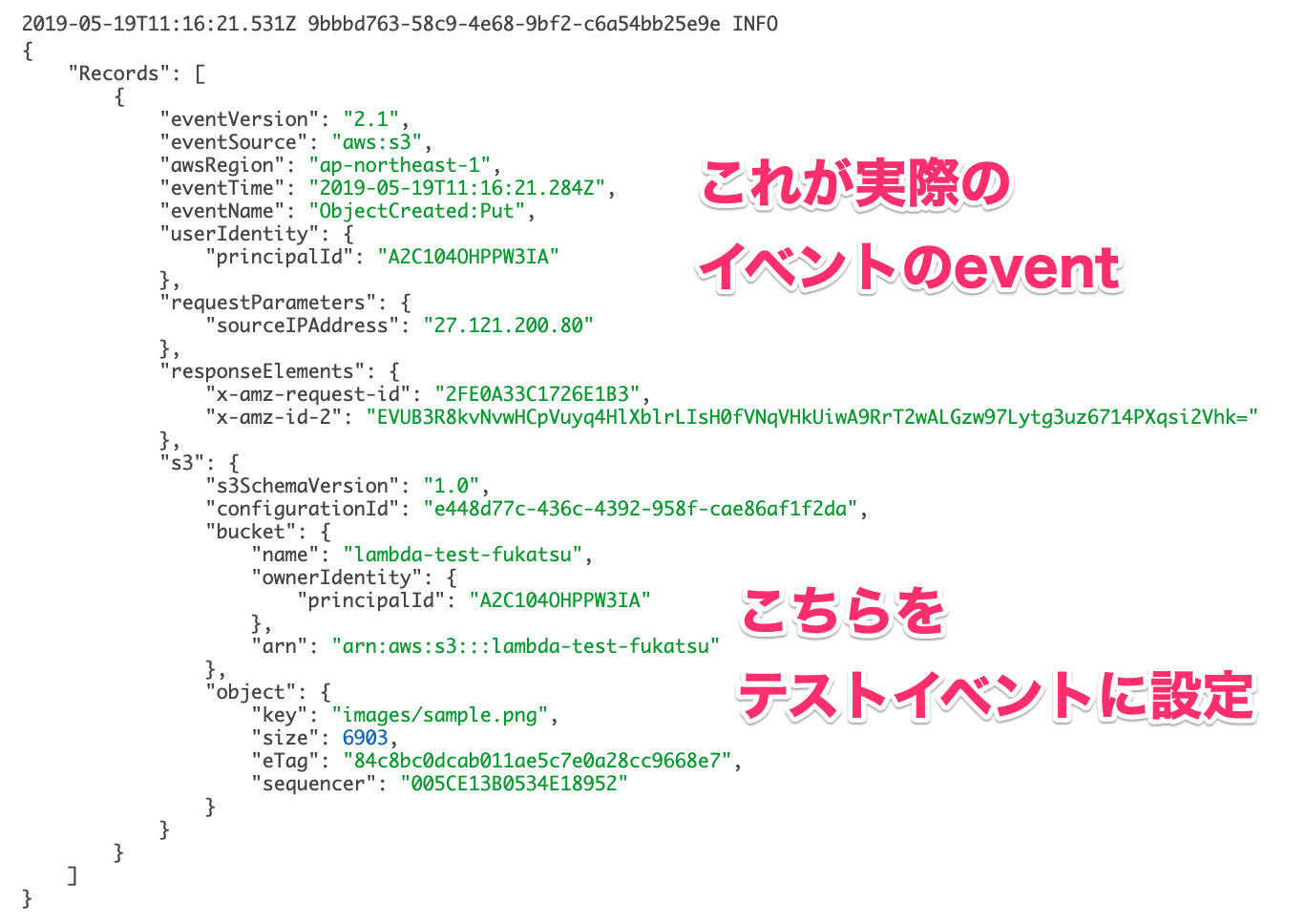
確認ができたら、この部分をテストイベントにコピペすれば、同じイベントをテストで再現することができるようになります。
S3のファイルのダウンロードとアップロード
ここからはS3のファイルのダウンロードとアップロードをできるようにしていきます。
ロールでS3へのアクセスを許可する
「実行ロール」から「ロールを表示」をクリックします。
ロールの画面に移動します。
↓「ポリシーをアタッチします」をクリックします。
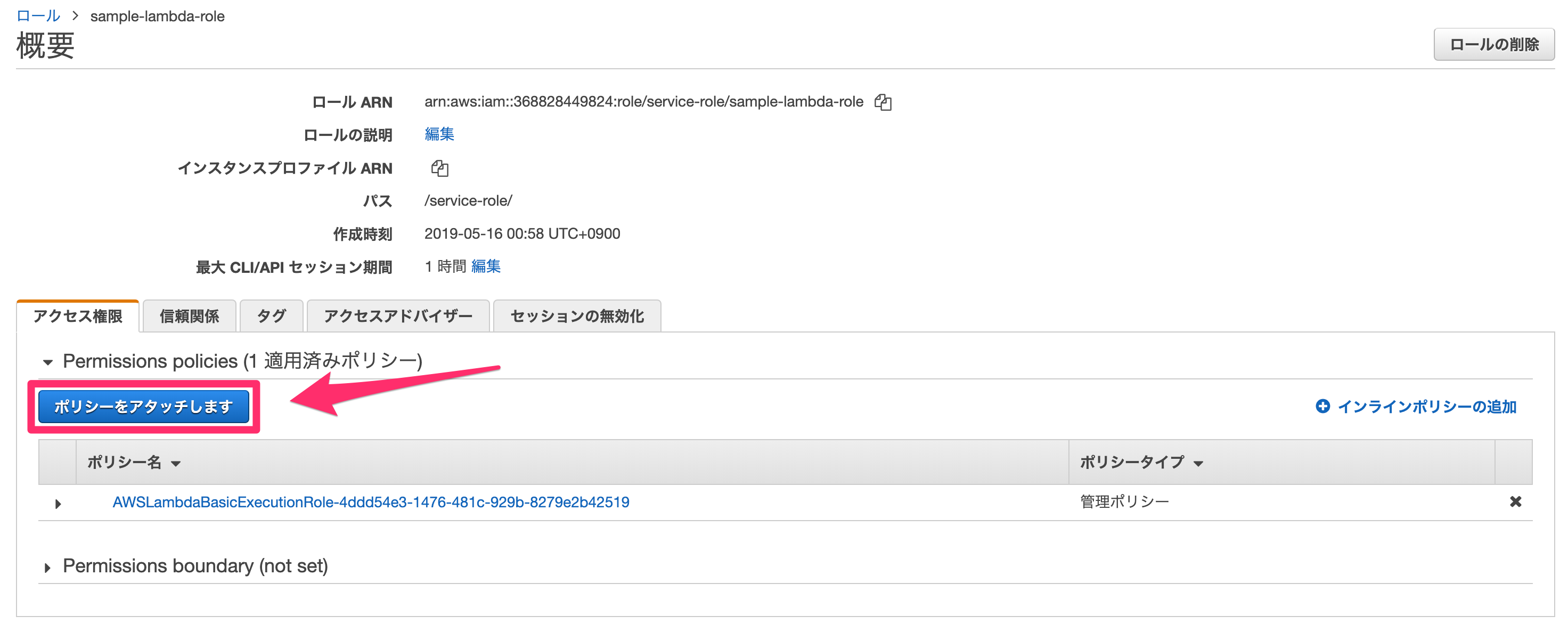
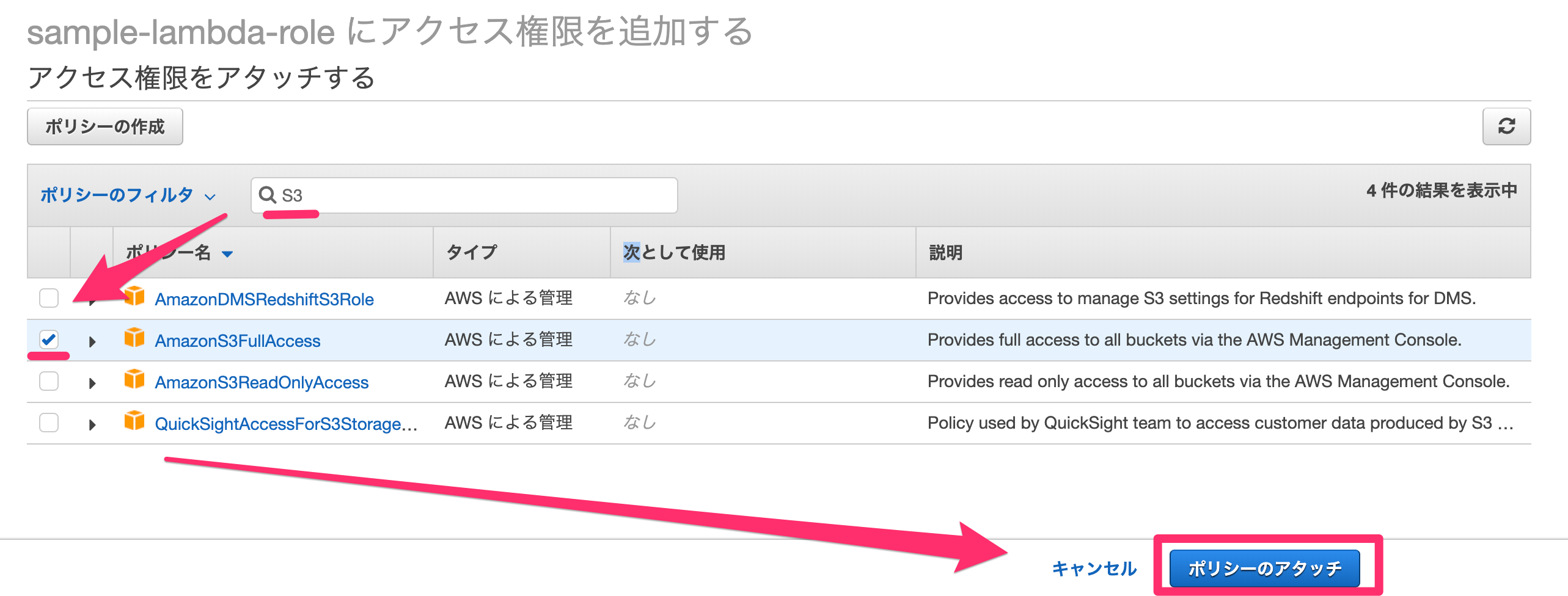
今回は、S3への全てのアクセスを許可するAmazonS3FullAccessをアタッチします。
↓チェックを入れて「ポリシーのアタッチ」をクリックします。
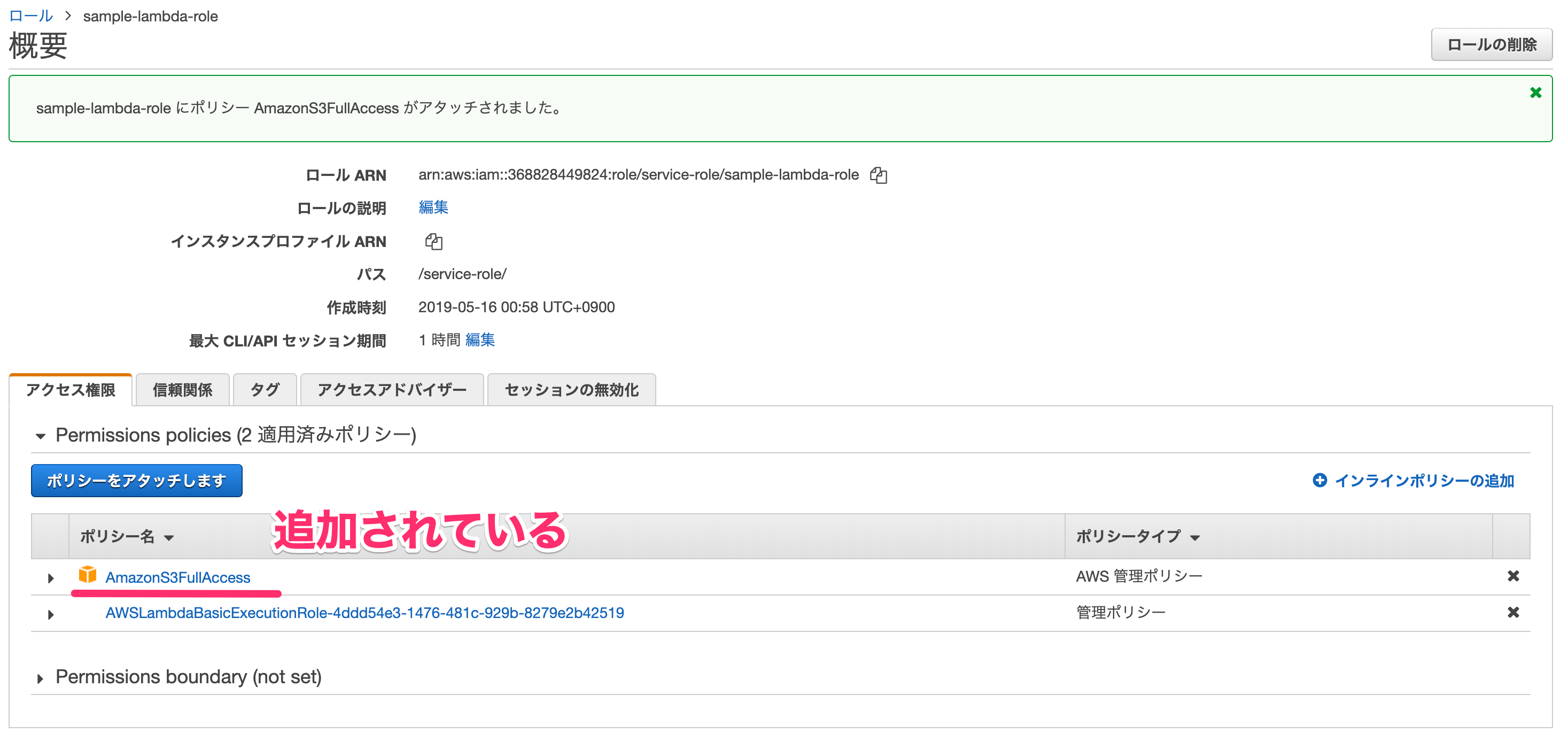
これでS3のアクセス権限が追加されました。
↓下記のスクショのように、ロールの画面にAmazonS3FullAccessが追加されているかと思います。
↓Lambdaの画面に戻ると、こちらでもAmazon S3がアクセス許可されているリソース一覧に追加されているかと思います。
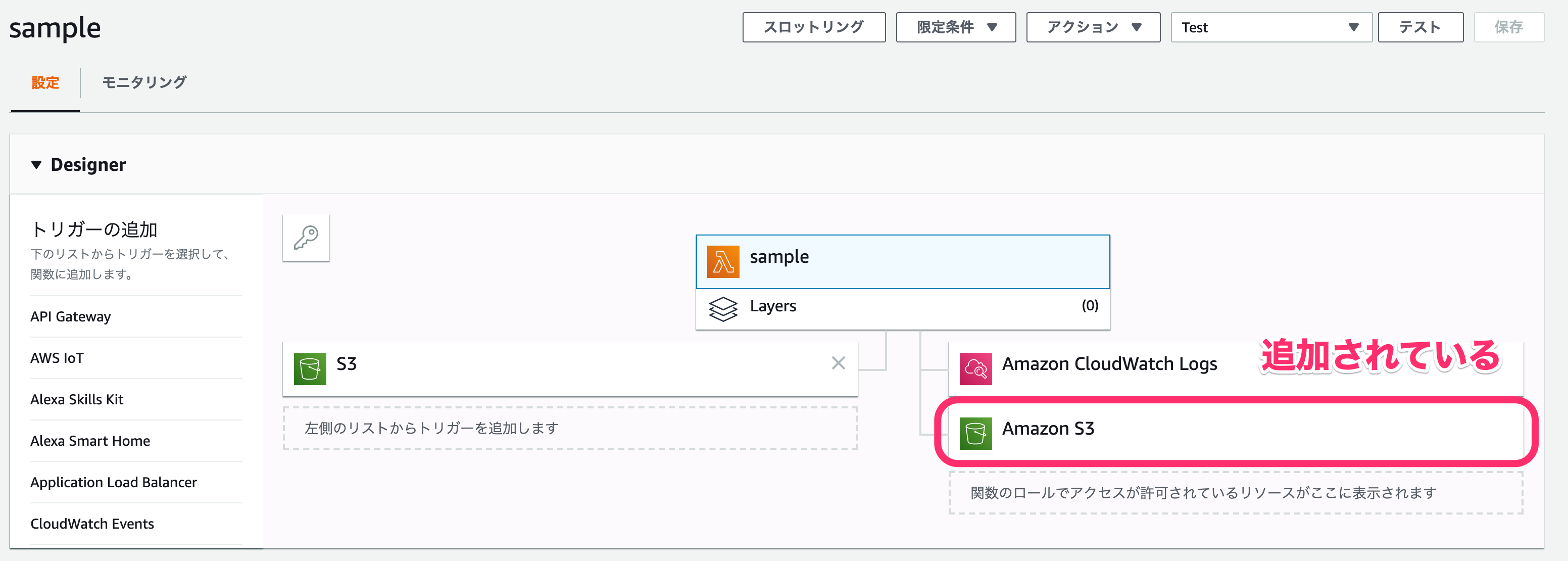
これでアクセス権限の追加が完了しました。
S3のファイルのダウンロードとアップロード
ここからはS3のファイルのダウンロードとアップロードを実装していきます。
ここまでだいぶ長くなりましたが、コードをいじっていきます。
今回は以下のように実装しました。
console.log('Loading function');
const aws = require('aws-sdk');
const s3 = new aws.S3({ apiVersion: '2006-03-01' });
exports.handler = async (event) => {
console.log('Received event:', JSON.stringify(event,));
const bucket = event.Records[0].s3.bucket.name;
const key = decodeURIComponent(event.Records[0].s3.object.key.replace(/\+/g, ' '));
const params = {
Bucket: bucket,
Key: key,
};
const uploaded_data = await s3.getObject(params)
.promise()
.catch((err) => {
console.log(err);
const message = `Error getting object ${key} from bucket ${bucket}. Make sure they exist and your bucket is in the same region as this function.`;
console.log(message);
throw new Error(message);
});
await s3.putObject({
Bucket: bucket,
Key: key.replace('images', 'images2'),
Body: uploaded_data.Body,
ContentType: uploaded_data.ContentType,
})
.promise()
.catch((err) => {
console.log(err);
const message = `Error putting object ${key} from bucket ${bucket}. Make sure they exist and your bucket is in the same region as this function.`;
console.log(message);
throw new Error(message);
});
return `Success getting and putting object ${key} from bucket ${bucket}.`;
};Node.jsで書く場合はコールバックが多くなってネストが深くなりがちですが、async awaitで書くことでそれを防ぐことが出来ます。
実装したコードに関して、1つずつ説明していきます。
まず、下記のコードでS3用の操作を行えるように読み込んでいます。
const aws = require('aws-sdk');
const s3 = new aws.S3({ apiVersion: '2006-03-01' });
S3からファイルをダウンロードする際に、バケット名とファイル名が必要になります。
eventにそれらの情報は入っているので整理します。
const bucket = event.Records[0].s3.bucket.name;
const key = decodeURIComponent(event.Records[0].s3.object.key.replace(/\+/g, ' '));
const params = {
Bucket: bucket,
Key: key,
};
以下でS3にアップロードされたファイルを関数内でダウンロードします。
const uploaded_data = await s3.getObject(params)
.promise()
.catch((err) => {
console.log(err);
const message = `Error getting object ${key} from bucket ${bucket}. Make sure they exist and your bucket is in the same region as this function.`;
console.log(message);
throw new Error(message);
});
以下でダウンロードしたファイルをそのまま同じバケットのimage2という名前の別のフォルダにアップロードします。
await s3.putObject({
Bucket: bucket,
Key: key.replace('images', 'images2'),
Body: uploaded_data.Body,
ContentType: uploaded_data.ContentType,
})
.promise()
.catch((err) => {
console.log(err);
const message = `Error putting object ${key} from bucket ${bucket}. Make sure they exist and your bucket is in the same region as this function.`;
console.log(message);
throw new Error(message);
});ではコードを保存して、テストを実行しましょう。
↓無事成功することが確認できました。
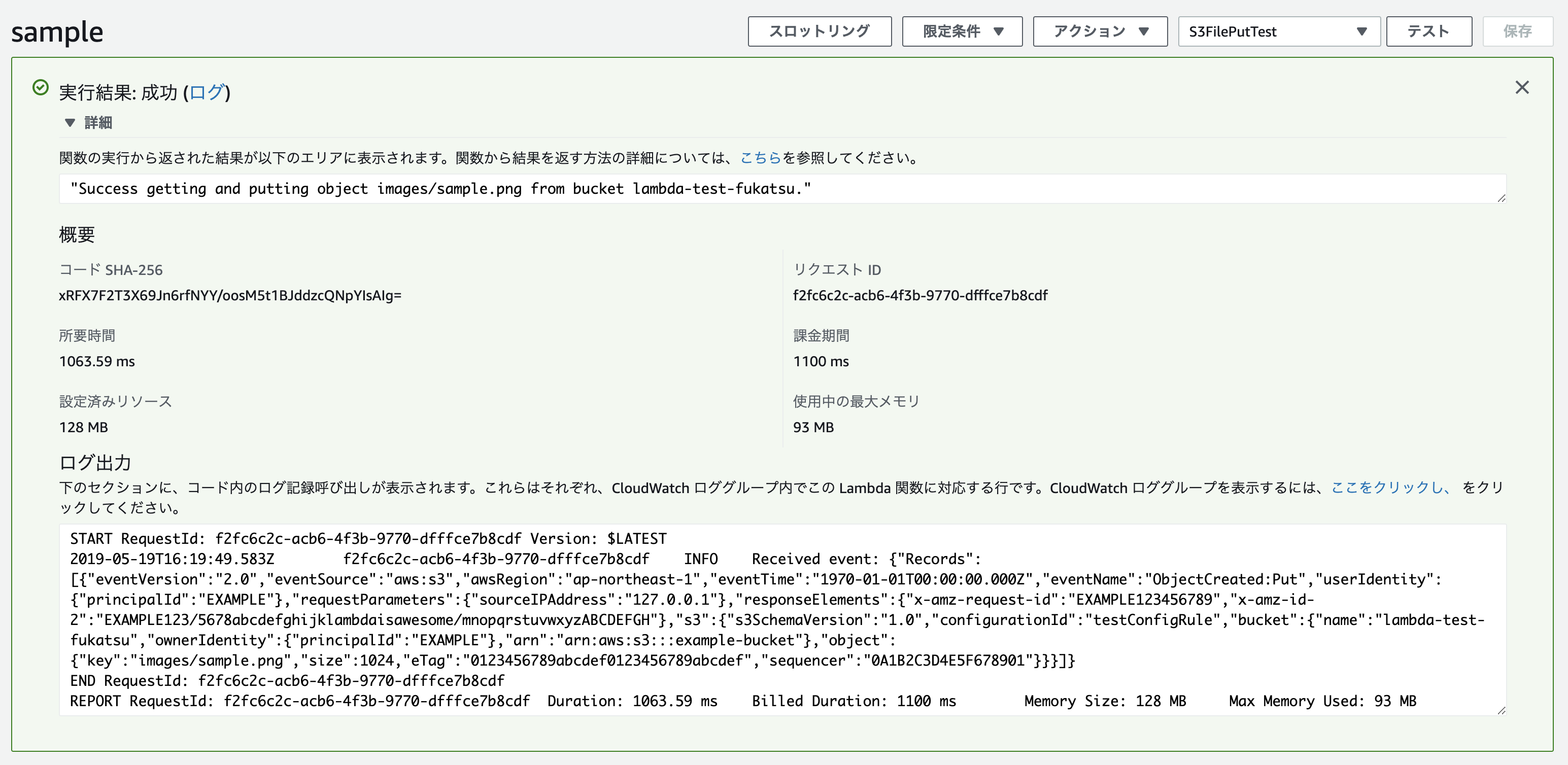
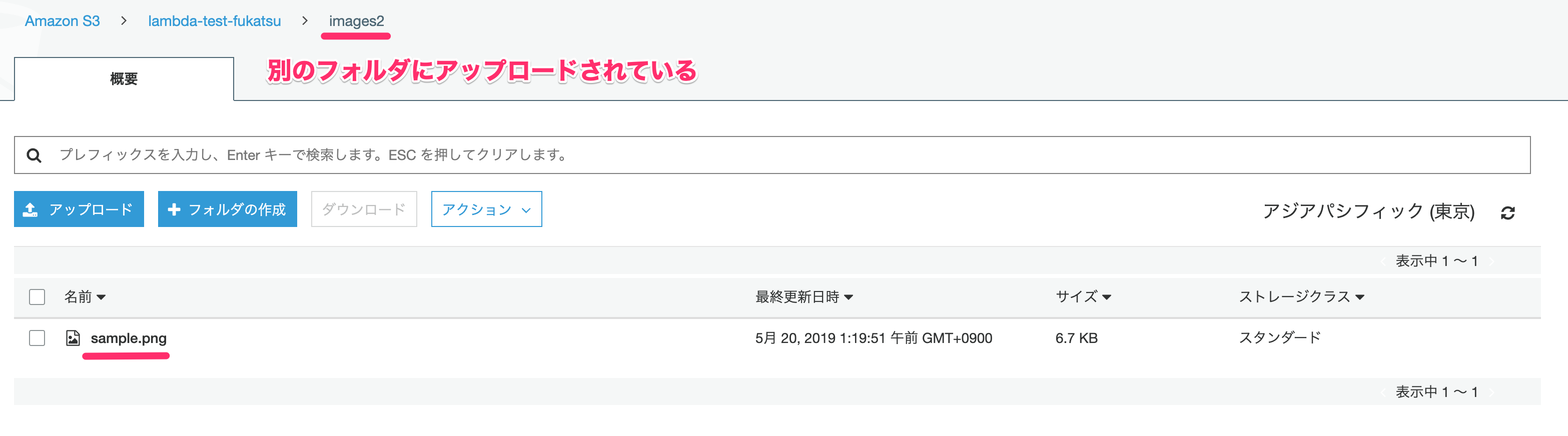
S3の画面も確認しましょう。
↓image2というフォルダが新しく作られていて、sample.pngがアップロードされていることが確認できました。
テストを行って確認をしましたが、実際にS3にアップロードを行って確認もしましょう。
ここでは結果は載せませんが成功しました。
これで全ての設定が終了です!
アップロードの際の注意
今回はS3のファイルをダウンロードして別のフォルダにアップロードを行いました。
その際に注意が必要です。
今回アップロードしたフォルダはトリガーで指定した範囲外のフォルダになります。
もし範囲内のフォルダにアップロードしてしまうと、アップロードした際にまたトリガーが発火して関数が起動してしまい、無限ループに陥ってしまう可能性があります。
もしアップロードする際にはその辺を注意しましょう。
まとめ
だいぶ長い内容になってしまいましたが、ここまで読んでいただきありがとうございました。
今回はLambdaを理解するために、画面の説明や実際に実装する手順を1つずつ説明していきました。
もしこの記事を読んでLambdaに関して理解していただけたら嬉しいです。
今回作成した関数は、基本を学ぶために最低限の機能しかやらなかったので、特に実用性があるわけではないものになってしまいました。
他の実装例
他にも具体的な用途で実装したものをまとめましたので、もし興味があれば参考にしてみてください。






